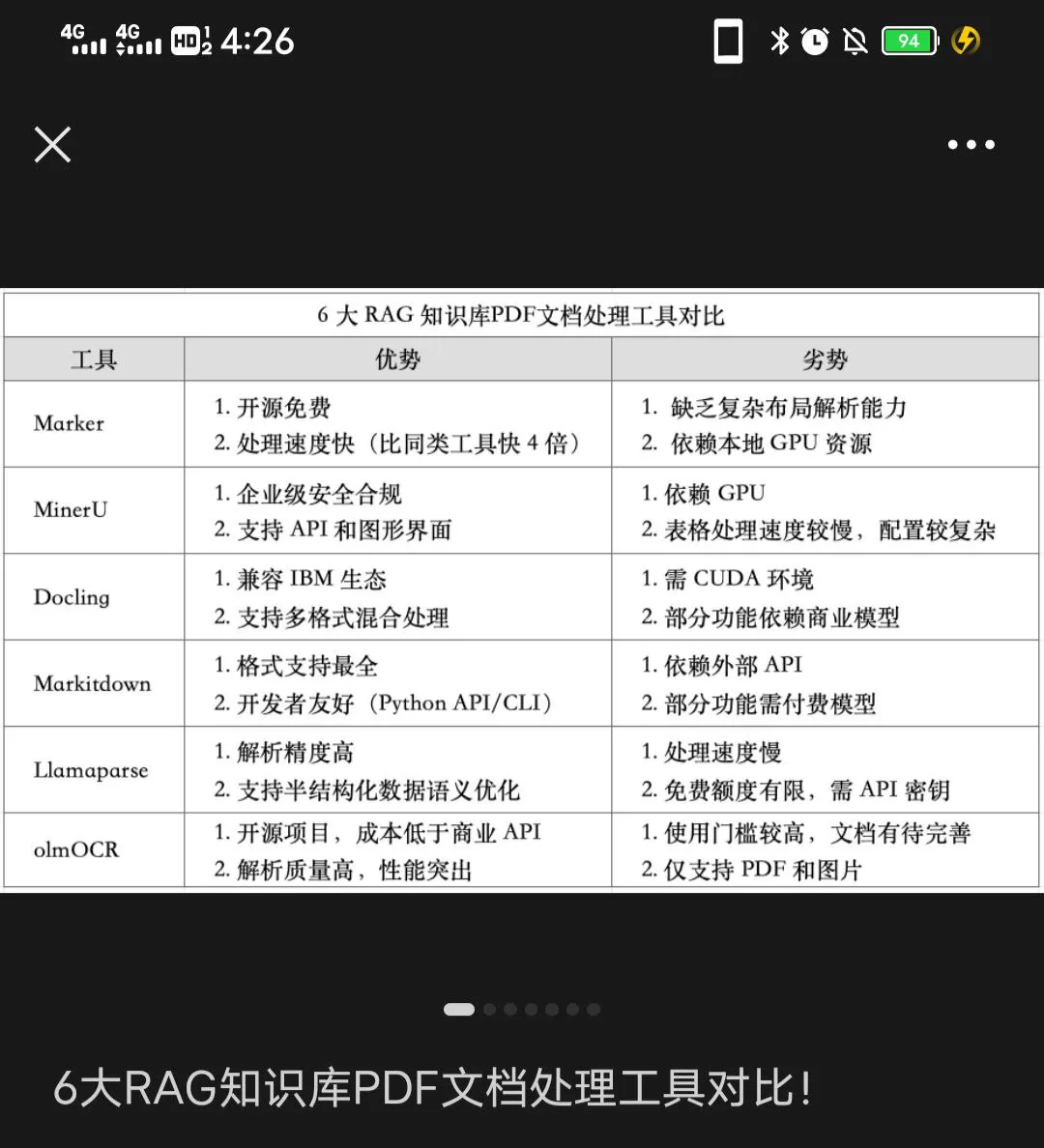
本帖罗列市面上的pdf转markdown工具,毕竟markdown文本更适合在RAG流程中传递给llm。
1、gemini 2.0模型
本质上也是用了ocr。效果还行。必须借助prompt让gemini分批次回复转换的结果。
我目前使用的prompt:
https://memos.gujiakai.top/m/A6Vix8xhMrupJwf9TM9UKt
目前阶段【截至2025.2.14】,gemini 2.0 exp模型对于图表、数学公式转换还是存在缺陷的,毕竟这些点目前最先进的ocr可能也难以应对。
考虑时间等成本,我的解决方案图表保留标题,去除掉图表【尽可能减小在RAG流程中的噪音,少掉的部分,如果真需要在RAG中输出,则通过citation的方式,让用户自寻查找解决方案】,数学公式摆乱,毕竟LLM对于数学也不是精通的那种。
补充一些gemini 2.0多模态能力,处理PDF数据的博文:
2、docling:Docling - Docling
对于图表、数学公式存在瑕疵,但是转换结果相较于PyMuPDF而言更棒,PyMuPDF的转换结果更零散。
近期PyMuPDF没试过,不清楚体验有无改进,但去年年底体验给我的感受就是docling更胜一筹。
而且最近在reddit上也看到有老哥称赞docling,综合成本和效果考虑,确实docling在这方面是很有竞争力。
用了多天mineru处理数据,发现docling处理相较mineru更有利于RAG流程中的chunk根据文档结构分块。
3、llamaparse:https://cloud.llamaindex.ai/
premium模式转换结果确实非常好,但可惜是闭源服务,有免费额度,但是对于一定数量的文件而言就需要破费了。

近期随着gemini 2.0 flash的正式上线,也第一时间集成了,但总体而言,还是受限于成本。
4、Doc2X:https://doc2x.noedgeai.com/
据说转换效果不错。但也属于是付费项目。
看演示视频很惊艳。没体验过,一般我都是直接用docling,以后可以尝试尝试。
需要高级LLM API,归根结底还是付费服务,为了转换质量,可以一试,如果一般转换就行,直接用docling更佳,开源项目,除了算力,不需要额外付费。
持续更新,还有很多选项。
不愧是大模型时代的文档提取/转换神器,转换效果比docling都要来得好。
而且是开源项目,如果懒得自部署,用官方的saas服务,可以申请api。
不好说孰优孰劣,只能说各有特色。完美转换是不存在的。
补充:
MinerU的最大优势:本地部署后可以接入LLM,为OCR加持,LLM越强,OCR效果越好。
听网友说的,有机会本地部署试试,接入Qwen VL/Gemini系列模型,成本和效果可以平衡。虽然很想尝试GPT/Claude,但价格劝退。
marker项目:GitHub - VikParuchuri/marker: Convert PDF to markdown + JSON quickly with high accuracy
粗看了一下页面,也有对应的saas api服务。效果不清楚如何,目前docling、mineru感觉够用了。
olmOCR:https://olmocr.allenai.org/
olmOCR 是一种开源工具,旨在将 PDF 和其他文档高吞吐量转换为纯文本,同时保持自然阅读顺序。它支持表格、方程式、手写等。
huggingface space:PDFParsersPlayground - a Hugging Face Space by chunking-ai
pdf 2 markdown游乐场。
mistral ocr:Mistral OCR | Mistral AI
看了simonwillison大神的测评,pdf转markdown还是差点意思。
mistral压根就没崛起过,一直在炒作。
没有完美的解决方案,docling、mineru也不是完美的解决方案,能做到90%+其实也已经够了,希望未来能有100%完美转换的解决方案。
结合docling和gemini的PDF转markdown工具。
还能生成表格、图片描述。
看起来不错,具体没试过。
又一个借助LLM的PDF转Markdown项目。

cloudflare的markdown转换功能:Markdown Conversion · Cloudflare Workers AI docs

网友做了一个demo站点:Office File to Markdown | HTML.ZONE
相关项目地址:GitHub - xxnuo/serverless-markdown-convertor: Markdown Conversion
我上传了一份pdf,看了一下转换效果,只能说还行,但比不上docling和mineru。
扫描件PDF转Markdown项目:[开源] 扫描件 PDF 转 Markdown / EPUB,自动修复 OCR 错误 - V2EX
Textin付费服务:

Gemini 2.5 Pro YYDS!!!!!